

/image%2F0832538%2F20171101%2Fob_c510df_img-0322.jpg)
traitement de signal
La sommation numérique

Ce mémoire a été réalisé par Bastien Prevosto et soutenu à l'Ecole nationale supérieure Louis Lumière, en juin 2012, sous les directions de Laurent Millot et Gaël Martinet.
L'auteur aborde un sujet sensible, et pas toujours très bien connu : la sommation numérique. Cette opération arithmétique est responsable de la qualité du signal obtenu en sortie d'un dispositif de mélange.
Résumé :
Lors d’un mixage audio-numérique, les signaux audio-numériques de chaque piste sont traités puis additionnés entre eux pour constituer un nouveau signal audio-numérique qui sera diffusé ou stocké.
La sommation numérique est l’opération de traitement du signal numérique qui correspond à cette addition des différents signaux audio-numériques à mixer.
Dans ce mémoire, nous voulons déterminer s’il existe des différences entre plusieurs versions d’un même mixage, réalisées par des logiciels de mixage audionumérique différents. Nous explorons donc les représentations binaires utilisées pour coder les signaux audio-numériques, notamment la représentation binaire en virgule flottante. La programmation d’un plug-in nous permet l’écoute des différences entre des traitements réalisés dans plusieurs précisions en représentation en virgule flottante. Enfin, nous rendons compte des résultats de tests réalisés avec
plusieurs logiciels effectuant un même mixage.
Mots clefs : Traitement du signal numérique, Représentation binaire en virgule
flottante, Erreurs d’arrondi, Sommation numérique, Mixage audio.
Lien : Téléchargement du mémoire de Bastien Prevosto " La sommation numérique".


Thèse de Greg Eustace Mc Gill University Montréal Canada
"Subjective evaluation of an autoregressive model-based method for the restoration of audio recordings contaminated with impulsive noise."
Thèse de Greg Eustace présentée à l'Université Mc Gill Montréal Canada. Octobre 2008.
Résumé :
De nombreux signaux musicaux d'intérêt historique sont stockés sur des supports analogues dégradés, tels que les enregistrements phonographiques.
La dégradation est souvent associée à des gênes sonores qui sont désagréables pour l'auditeur. La restauration audio utilise les technologies de traitement du signal numérique pour réduire ces artefacts associés aux bruits des signaux audionumériques. La restauration des clics, en particulier, s'attaque à la corruption du signal par des bruits impulsifs.
Ce projet a permis de développer un logiciel de restauration de clics, lequel utilise une méthode fondée sur le modèle auto-régressif bien connu pour détecter et supprimer les clics. Les résultats de la restauration ont été évalués subjectivement par des auditeurs experts, qui ont comparé la qualité sonore associée aux enregistrements phonographiques restaurés par la méthode d'auto-corrélation avec celle d'un système matériel de restauration très respecté et disponible commercialement.
Cette thèse reprend les travaux précédents sur la restauration audio, décrit la conception et la mise en œuvre du logiciel de restauration, explique la procédure d'évaluation, indique les résultats obtenus, dresse les conclusions et propose des suggestions de travaux futurs.
Téléchargement de la thèse G.Eustace (format .pdf) Numéro de publication : MR53518. 85 pages.
Le traitement du signal dans la restauration sonore (Partie 2)
Cette seconde partie du traitement de signal dans la restauration sonore concerne les bruits impulsionnels.
Les notes bibliographiques concernent les deux articles.
2 Bruits impulsionnels.
Les enregistrements anciens présentent généralement des défauts qui n'affectent que de courts instants de l'enregistrement. Parmi ceux-ci, on distingue en général deux types de dégradations :
Les bruits impulsionnels (impulsive-noise ou clicks en anglais) qui ont une durée extrêmement brève, de l'ordre de la milliseconde. Les bruits impulsionnels qui sont en général très nombreux (plus de 4000 en moyenne pour un morceau musical complet issu d'un disque 78 tours) constituent l'essentiel des défauts localisés présents sur les disques analogiques.
Les craquements (ou scratches en anglais) qui perturbent le signal durant des durées beaucoup plus importantes de l'ordre de la vingtaine de millisecondes. Les craquements correspondent à des dégradations importantes du support de l'enregistrement.
Dans, la suite on présente la technique la plus utilisée actuellement pour le traitement des bruits impulsionnels.


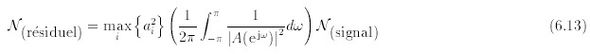

Localisation du bruit impulsionnel par filtrage adapté.
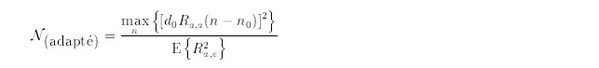

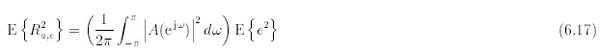
La quantité entre parenthèse qui correspond à l'énergie totale de la réponse impulsionnelle du filtre inverse A(z) est égale au terme R a,a (0) qui figure au numérateur de (6.16) (théorème de Parseval). En reportant (6.17) dans (6.16) on déduit donc que le niveau relatif du bruit impulsionnel vérifie

On note au passage que la limite de détection associée au filtre adapté ne dépend que de l'énergie du signal recherché (au numérateur) et de la puissance du bruit blanc dans lequel il est noyé (au dénominateur) [Van Tress 68]. Par suite, en faisant apparaître l'expression du niveau relatif du bruit impulsionnel N(résiduel) défini par (6.11) on obtient
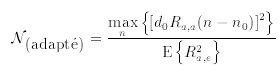
On obtient donc une relation analogue à (6.14) qui décrit le gain obtenu lors du filtrage adapté

L'étape de filtrage adapté se traduit donc bien par un gain, puisque le terme de droite dans l'équation ci-dessus et forcément supérieur à 1. De plus, ce gain est d'autant plus important que la réponse impulsionnelle A(z) est "étendue", c'est-à-dire qu'elle présente plusieurs termes d'amplitudes comparables.
Le principal intérêt du filtrage adapté est de permettre une localisation plus précise du défaut, en effet, l'étalement du bruit impulsionnel dû au filtrage par A(z) lors du passage au résiduel peut rendre dicile la location du bruit impulsionnel. Or nous avons vu que le filtrage adapté permet de déterminer sans ambiguïté la position du bruit impulsionnel.
Mise en œuvre
La procédure complète de détection des bruits impulsionnels est représentée par le schéma de la figure 6.5. Où la première étape de filtrage correspond au passage au signal résiduel, tandis que le filtrage par A(z-1) (réponse impulsionnelle du filtre inverse retournée ) et le seuillage représentent la détection par filtrage adapté.
On note qu’il est nécessaire d’estimer la puissance du signal résiduel afin de fixer le seuil de détection. Plus précisément la relation (6.15 ) montre que pour obtenir un taux de fausses alarmes fixé, le signal sur lequel on doit appliquer le seuil est
![]()
(se souvenir que R a,e(n) est un signal gaussien) [Van Tress 68 ]. La réponse A(z) étant connue, et en utilisant le résultat (6.17), le seul paramètre à déterminer est bien E {e2}.
Une remarque est que cette puissance ne correspond pas au σ2 fourni par la modélisation AR du fait de la présence du bruit

Figure 5 : Schéma de principe de la détection des bruits impulsionnels.
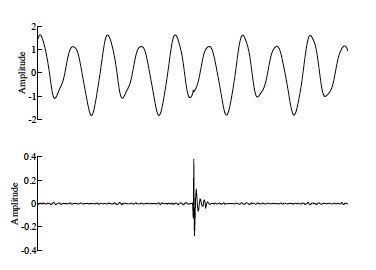
Figure 6 : Détection d'un bruit impulsionnel. En haut, le signal original, le niveau relatif du bruit impulsionnel est de -18 dB (rapport 1/8 en amplitude). En bas, le signal résiduel après filtrage adapté.
Dans le cas général, la procédure d'interpolation obtenue est assez lourde à mettre en œuvre puisque la résolution du système implique l'inversion d'une matrice de dimension ι × ι, où ι est le nombre d'échantillons à interpoler. Toutefois, si tous les échantillons à interpoler sont consécutifs, la matrice à inverser présente une structure particulière dite de Toeplitz.
L'inversion de cette matrice peut alors être réalisée de manière beaucoup moins coûteuse grâce à l'algorithme de Levinson [Press 86]. Pour les bruits impulsionnels, il est donc toujours plus efficace d'interpoler séparément chaque défaut pour se ramener au cas d'échantillons consécutifs.
Toutefois, ceci n'est possible que si les bruits impulsionnels sont séparés d'au moins p (ordre du modèle AR) échantillons de signal sans défauts. En effet, si les zones à interpoler sont trop proches il devient impossible de considérer les défauts séparément, il est alors nécessaire de réaliser l'interpolation globale (donc coûteuse).
Avec cette méthode, l'interpolation de zones de signal allant jusqu'à plusieurs dizaines d'échantillons successifs est quasiment inaudible pour la plupart des signaux audio [Jansen 86].
Bibliographie :
[Boll 79] S. F. Boll. Suppression of acoustic noise in speech using spectral substraction. IEEE Trans. Acoust., Speech, Signal Processing, vol. 27 (2), pp. 113{120, 1979.
[Brillinger 81] D. R. Brillinger. Time Series Data Analysis and Theory. Holden-Day, expanded edition, 1981.
[Cappe 93] O. Capp_e. Techniques de R_eduction de Bruit pour la Restauration d'Enregistrements Musicaux. PhD thesis, ENST, Sep 1993.
[Charbit 90] M. Charbit. Eléments de théorie du Signal: les signaux aléatoires. Collection Pédagogique de Télécommunication. Ellipse, Paris, 1990.
[Ephraim 84] Y. Ephraim and D. Malah. Speech enhancement using a minimummean-square error short-time spectral amplitude estimator. IEEE Trans. Acoust., Speech, Signal Processing, vol. 32 (6), pp. 1109{1121, 1984.
[Jansen 86] A. J. E. M. Jansen, R. N. J. Veldhuis, and . B. Vries. Adaptive interpolation of discrete-time signals that can be modelled as autoregressive processes. IEEE Trans. Acoust., Speech, Signal Processing, vol. 34 (2), pp. 317{330, 1986.
[Kay 88] S. M. Kay. Modern Spectral Estimation. Prentice Hall, Englewood Cli_s, NewJersey, 1988.
[Lim 79] J. S. Lim and A. V. Oppenheim. Enhancement and bandwidth compression of noisy speech. Proc. IEEE, vol. 67 (12), Dec 1979.
[Lim 83] J. S. Lim. Speech enhancement. Prentice-Hall signal processing series. Prentice-Hall, 1983.
[Makhoul 75] J. Makhoul. Linear prediction: A tutorial review. Proc. IEEE, vol. 63 (11), pp. 1380{1418, Nov 1975.
[Press 86] W. H. Press. Numerical Recipes, The Art of Scienti_c Computing. Cambridge University Press, Cambrige, 1986.
[Van Tress 68] H.L. Van Tress. Detection, Estimation and Modulation Theory. Wiley, New York, 1968.
Le traitement du signal dans la restauration sonore (Partie 1)
Le traitement du signal dans la restauration sonore est un extrait du document intitulé " Traitement des Signaux Audio-Fréquences de Jean Laroche ,département Signal, Groupe Acoustique TELECOM.
Cette première partie est consacrée à la méthode de la soustraction de puissance utilisée dans l'atténuation du niveau de bruit de fond.
La seconde partie sera consacré aux bruits impulsionnels.
Les références bibliographiques seront publiées à la fin de la seconde partie.
La restauration d'anciens enregistrements par des techniques de traitement du signal est un domaine qui s'est développé avec la généralisation de l'audionumérique, c'est-à-dire depuis environ une dizaine d'années. Il existe maintenant plusieurs systèmes commerciaux qui permettent de traiter des anciens enregistrements en temps réel. Il faut toutefois avoir conscience du fait que ce type de technique ne peut être efficace que si les démarches préliminaires au traitement ont été réalisées avec soin. Ces démarches peuvent être, par exemple, la sélection d'un enregistrement original (recherche historique et musicologique) et le choix d'une technique de transfert adapté au support de l'enregistrement (ce qui suppose des connaissances historiques ainsi que l'utilisation d'un système mécanique approprié). On peut aussi imaginer (et c'est ce qui est souvent fait) de retravailler l'enregistrement historique à la manière de l'ingénieur du son, étant entendu que ce sont alors des compétences artistiques qui guident le traitement.
La partie abordée dans la suite de ce chapitre concerne uniquement l'aspect "signal", c'est-à-dire l'élimination des dégradations présentes sur l'enregistrement dont on suppose qu'il a déjà été transféré de manière adéquate sous forme numérique.
1 Bruit de fond
1.1 Principe du traitement
Les références [Lim 79] [Lim 83] présentent un panorama des techniques de réduction de bruit utilisées pour les signaux de parole au début des années 80. Ces techniques s'appliquent aussi, pour la plupart, au cas des anciens enregistrements, toutefois il est nécessaire de prendre en compte deux aspects importants :
- On ne dispose en général que d'une seule copie de l'enregistrement, ce qui exclue les méthodes de type multi capteurs.
- Compte tenu de la diversité des signaux musicaux présents sur les enregistrements, il est difficile d'émettre des hypothèses sur la nature du signal. En conséquence beaucoup de méthodes utilisées pour le débruitage de signaux de parole ne sont pas directement utilisables pour les anciens enregistrements (par exemple, lorsqu'elles supposent que le signal est quasi-périodique).
Dans ces conditions, les techniques utilisées pour la restauration d'enregistrements musicaux fonctionnent généralement selon le principe d'atténuation spectrale à court terme qui consiste à effectuer une analyse du signal bruité par transformée de Fourier à court terme, puis à atténuer certains points des spectres à court terme. L'atténuation apportée est d'autant plus importante que le niveau du spectre à court terme est proche d'une estimation spectrale de la puissance du bruit de fond Pd(ωk). La mesure de la densité spectrale de puissance du bruit de fond est en général réalisée au préalable à partir d'un morceau de bruit seul pris en début ou en fin de l'enregistrement. Ceci suppose que le bruit de fond soit stationnaire tout au long de l'enregistrement. Le schéma de principe d'une telle technique est représenté par la figure 1. Dans ce schéma, la règle de suppression désigne le mécanisme qui permet de calculer l'atténuation à apporter à chaque point de la transformée à court terme.
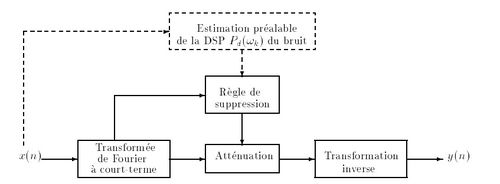
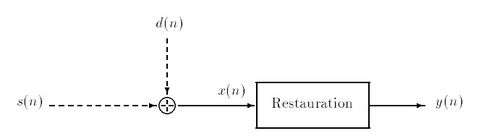
Figure 2 : Notations
Le bruit de fond étant supposé stationnaire, la quantité E ne dépend pas de l'indice temporel p, elle est égale à l'espérance du périodogramme du bruit (défini comme le module au carré de la transformée de Fourier discrète). On peut montrer que cette quantité constitue bien une estimation de la densité spectrale de puissance du bruit de fond [Kay 88] [Brillinger 81], on choisit donc de noter :
![]()
L’équation 6.1 devient donc :
![]()
ce qui peut s’écrire à nouveau :
![]()
Cette dernière relation va nous permettre de définir le signal restauré y(n). Pour mettre, en évidence l'atténuation apportée à chaque point du spectre à court terme, on écrit que le spectre à court terme du signal restauré est obtenu comme suit :

ce qui implique :
![]()
C'est cette forme qui est à l'origine de la dénomination de la soustraction en puissance. En comparant les relations (6.6) et (6.4), il apparaît que le signal y(n) restauré vérifie la propriété suivante :
![]()
On obtient donc une estimation non biaisée du carré du module de la transformée de Fourier à court terme du signal inconnu. Ceci est intéressant car on sait que des sons qui présentent des transformées de Fourier à court terme semblables en module sont perçus comme étant très proches à l'écoute (c'est le principe du spectrogramme où l'on ne représente que le module des spectres à court terme). Attention toutefois, cette propriété est loin d'être infaillible et il est très facile de trouver des contres exemples. Cependant, la relation (6.7) garantit tout de même en pratique une forte ressemblance du signal restauré y(n) avec le signal original inconnu lors de l'écoute.
Il faut cependant remarquer que l'estimation obtenue en pratique est tout de même biaisée pour les faibles valeurs du spectre. Ceci vient du fait que la quantité définie par l'équation (6.6) n'est pas forcément positive. Afin de préserver le sens physique de Y (p,ωk)2 (et de pouvoir synthétiser un signal temporel), on choisit en général de forcer à zéro les valeurs négatives.
La règle de suppression dite de soustraction en puissance s'écrit donc :
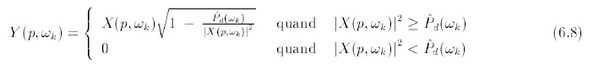
mais ceci n'est vrai qu'en moyenne.

Figure 3 : Exemple de modification spectrale par la règle de soustraction en puissance : Cas d'un signal de fort niveau. A gauche, le spectre original X (p,ωk) avec en pointillé l'estimation de la densité spectrale du bruit de fond Pd(ωk) (ici un bruit blanc). A droite, le spectre modifié ,Y (p,ωk). Seule une partie des spectres est représentée.

Figure 4 : Exemple de modification spectrale par la règle de la soustraction en puissance. Cas d'un instant de silence. A gauche, le spectre original X (p,ωk),avec en pointillés l'estimation de la densité spectrale du bruit de fond Pd(wk) (ici un bruit blanc). A droite, le spectre modifié Y (p,ωk). Seule une partie des spectres est représentée.
Si on ne considère qu'une seule trame à court terme (c'est-à-dire une seule réalisation), on constate une grande disparité entre X (p,ωk)2 et ce qui est une propriété bien connue du périodogramme [Kay 88]. C'est le moyennage effectué sur plusieurs fenêtres distinctes qui garanti l'aspect lisse de Pd(ωk), il n'en va pas de même pour X (p,ωk)2. Le point gênant est que, dans une zone de silence, X (p,ωk)2 est susceptible de prendre des valeurs nettement plus grandes que Pd(ωk). Ces valeurs du spectre à court terme sont donc peu atténuées puisque rien ne les différencie des composantes de signal de bas niveau. En conséquence le spectre du signal en sortie présente des pics (cf. partie droite de la figure 4).
La présence de ces pics, dont les positions varient aléatoirement d'une trame à court terme à l'autre, se traduit par un phénomène audible et peu naturel connu sous le nom de bruit musical. La solution la plus intuitive à ce problème consiste à surestimer le niveau de bruit de fond, c'est-à-dire à multiplier Pd(ωk) par un facteur supérieur à 1. On conçoit en effet que si l'estimation du bruit de fond (en pointillés sur la partie gauche de la figure 4) est artificiellement surélevée jusqu'à passer au dessus des variations de X (p,ωk)2, alors le spectre modifié sera bien identiquement nul. L'inconvénient de cette solution c'est que l'atténuation apportée aux valeurs du spectre à court terme, qui correspondent au signal devient de plus en plus importante ce qui finit par créer des distorsions audibles du signal. Plusieurs autres solutions à ce problème ont été proposées, on en trouvera des exemples dans [Boll 79] ou dans [Ephraim 84].
